Generate your kluster.ai API key#
The API key is a unique identifier that authenticates requests associated with your account. You must have at least one API key to access kluster.ai's services.
This guide will help you obtain an API key, the first step to leveraging kluster.ai's powerful and cost-effective AI capabilities.
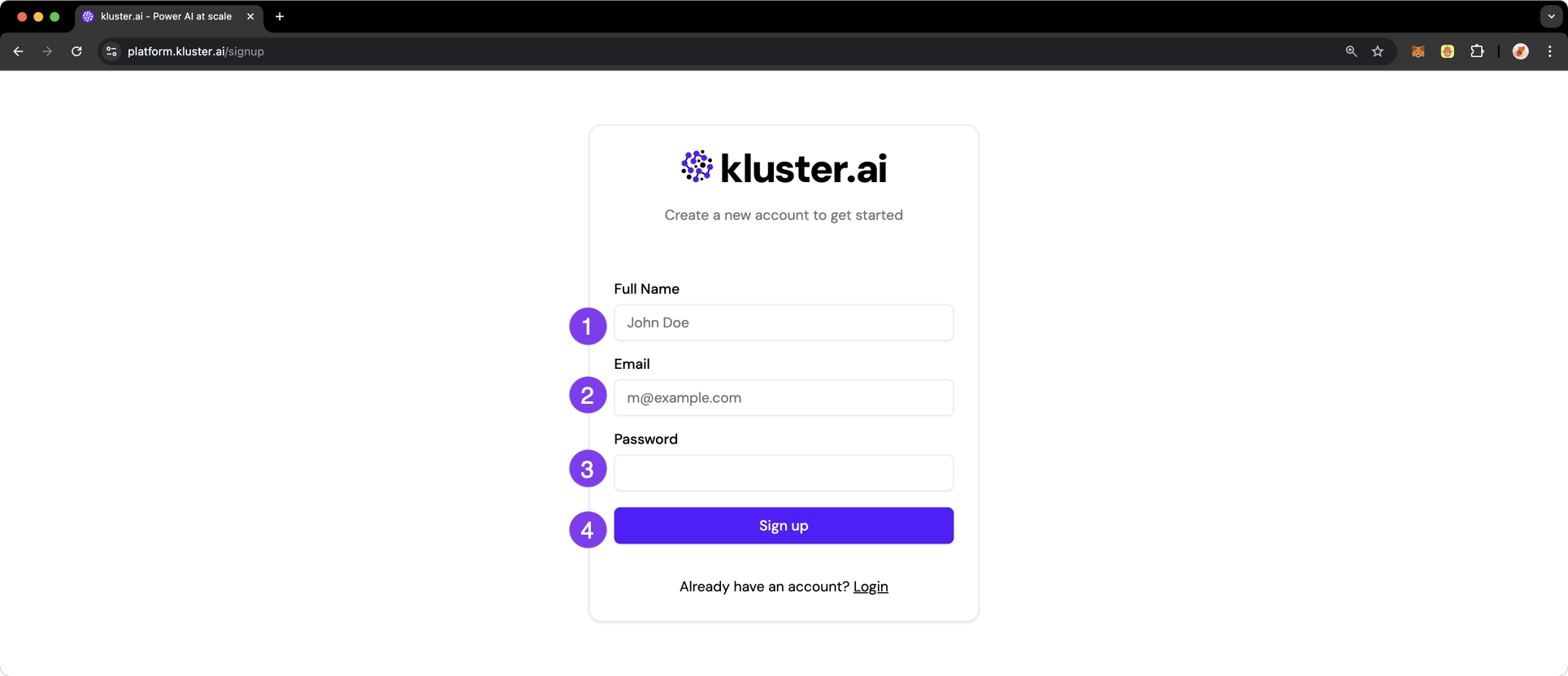
Create an account#
If you haven't already created an account with kluster.ai, visit the registration page and take the following steps:
- Enter your full name
- Provide a valid email address
- Create a secure password
- Click the Sign up button
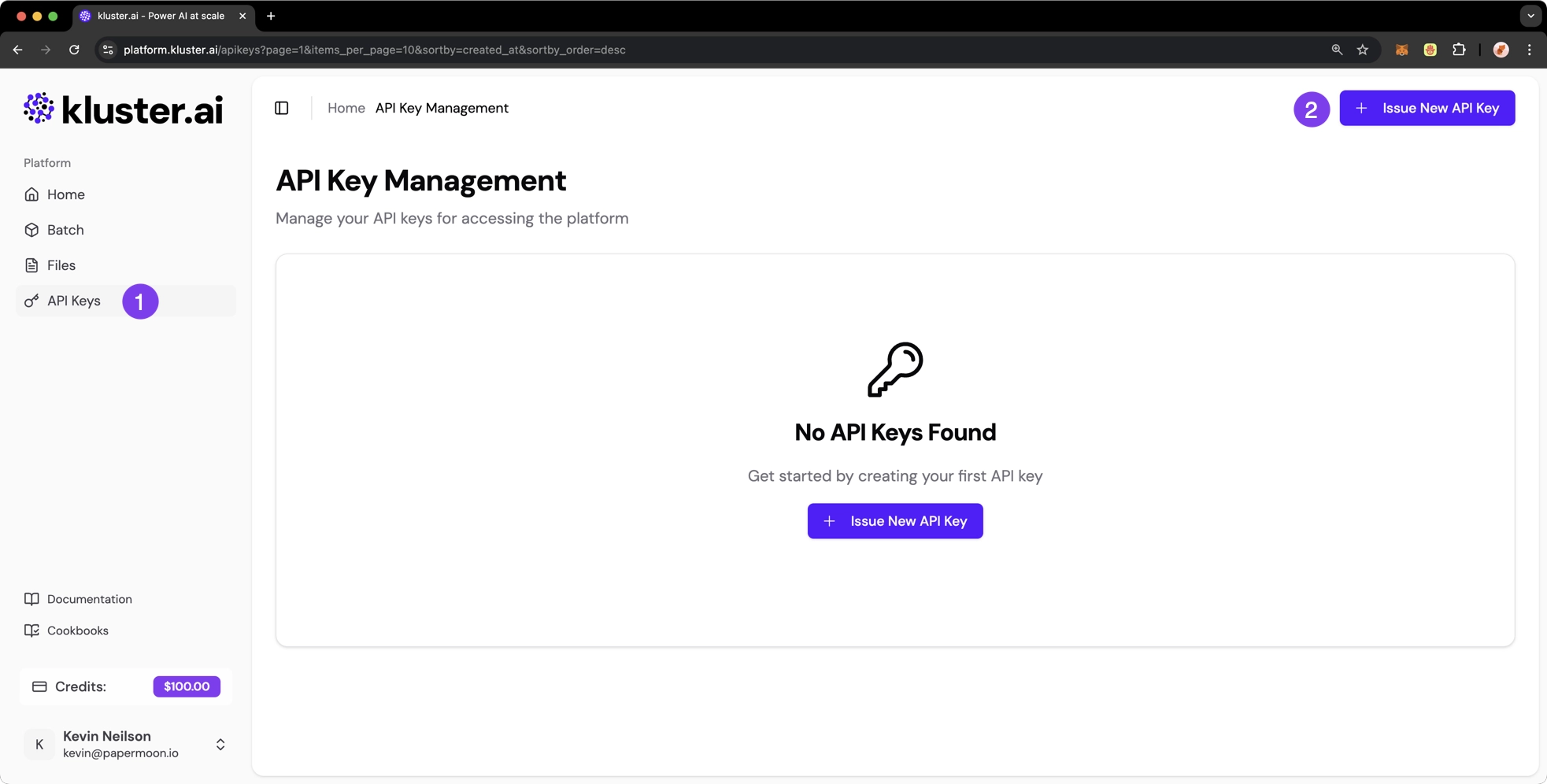
Generate a new API key#
After you've signed up or logged into the platform through the login page, take the following steps:
- Select API Keys on the left-hand side menu
-
In the API Keys section, click the Issue New API Key button
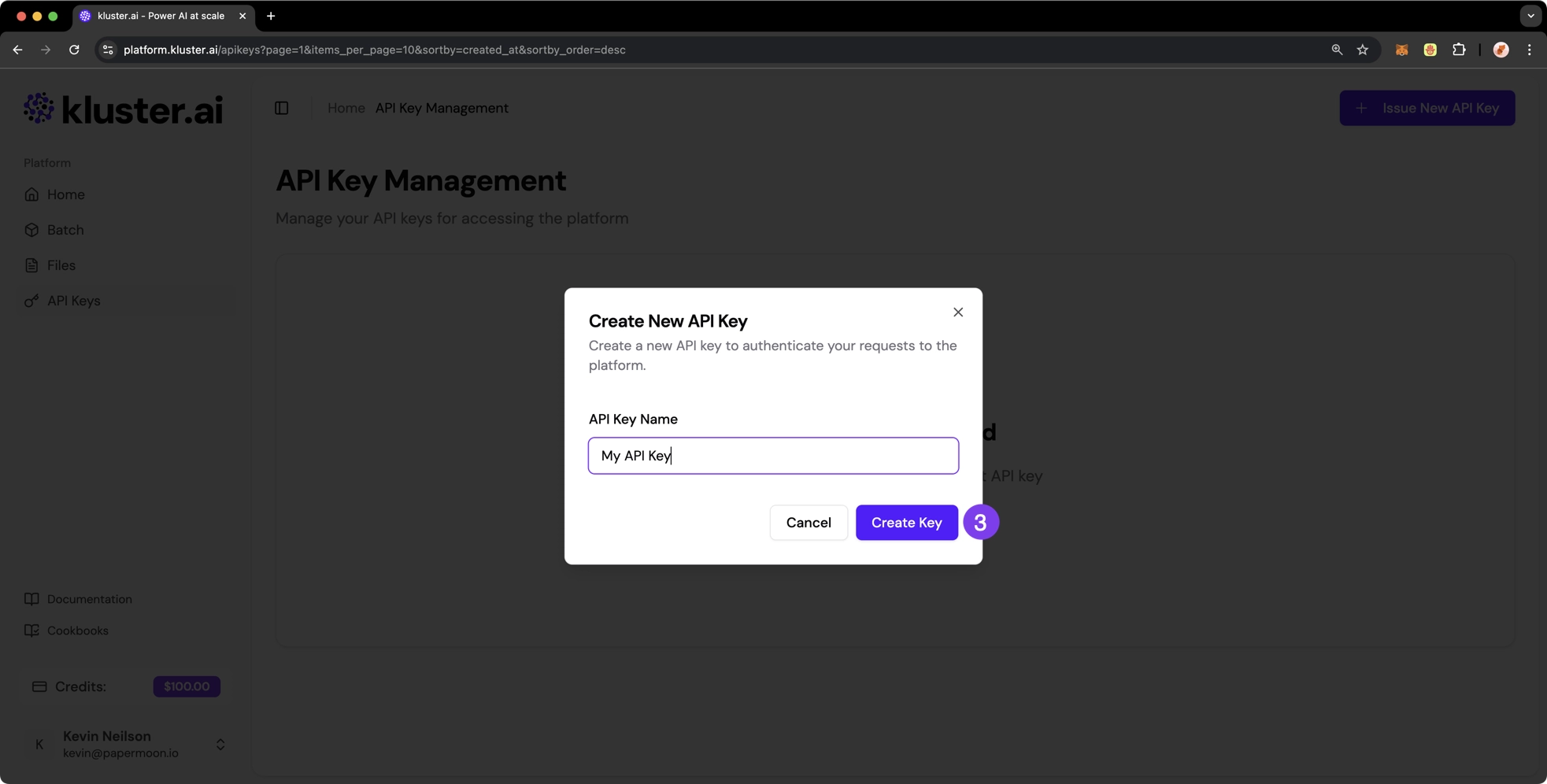
-
Enter a descriptive name for your API key in the popup, then click Create Key
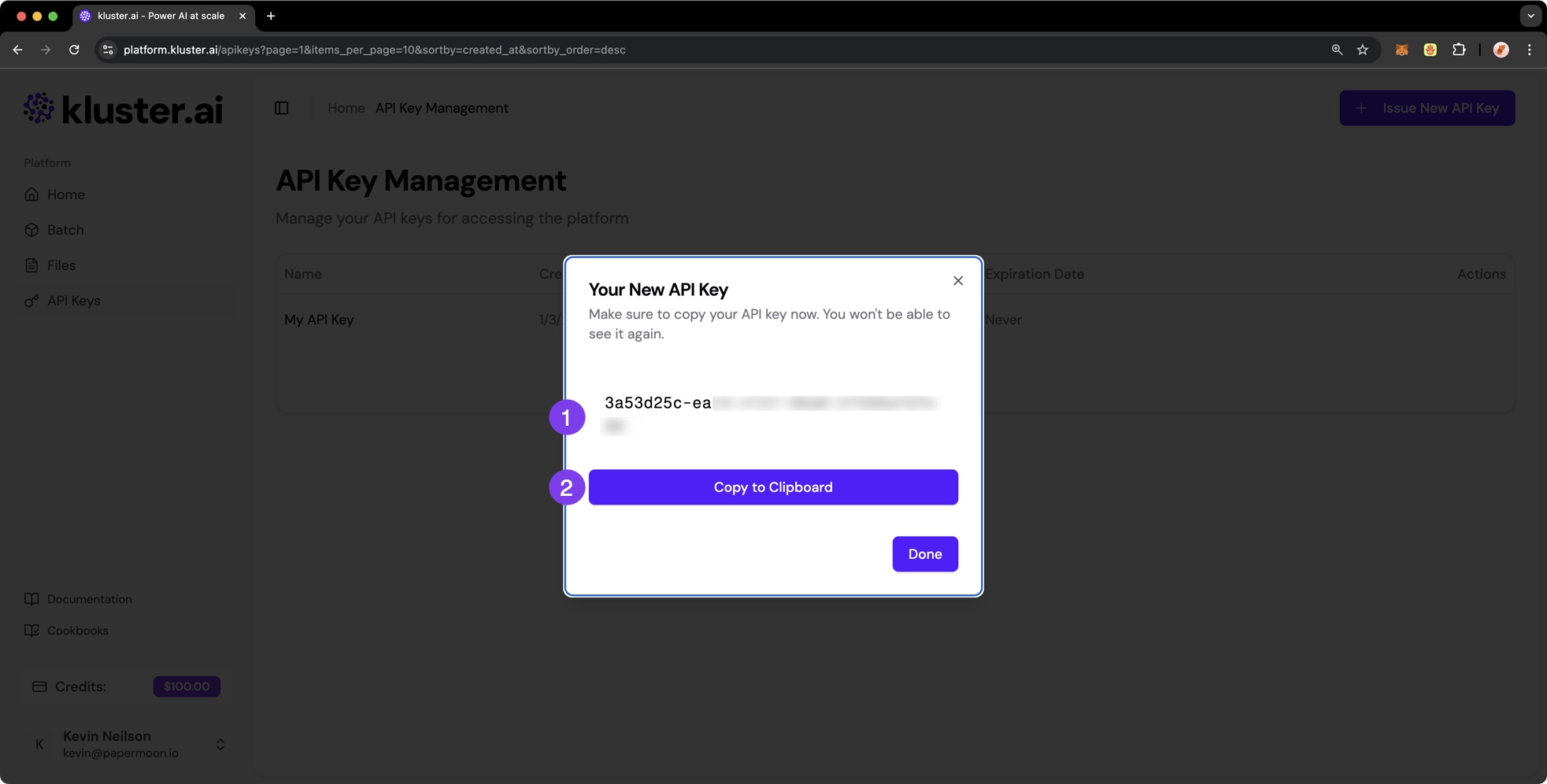
Copy and secure your API key#
- Once generated, your API key will be displayed
-
Copy the key and store it in a secure location, such as a password manager
Warning
For security reasons, you won't be able to view the key again. If lost, you will need to generate a new one.
Security tips
- Keep it secret - do not share your API key publicly or commit it to version control systems
- Use environment variables - store your API key in environment variables instead of hardcoding them
- Regenerate if compromised - if you suspect your API key has been exposed, regenerate it immediately from the API Keys section
Managing your API keys#
The API Key Management section allows you to efficiently manage your kluster.ai API keys. You can create, view, and delete API keys by navigating to the API Keys section. Your API keys will be listed in the API Key Management section.
To delete an API key, take the following steps:
- Locate the API key you wish to delete in the list
- Click the trash bin icon ( ) in the Actions column
- Confirm the deletion when prompted
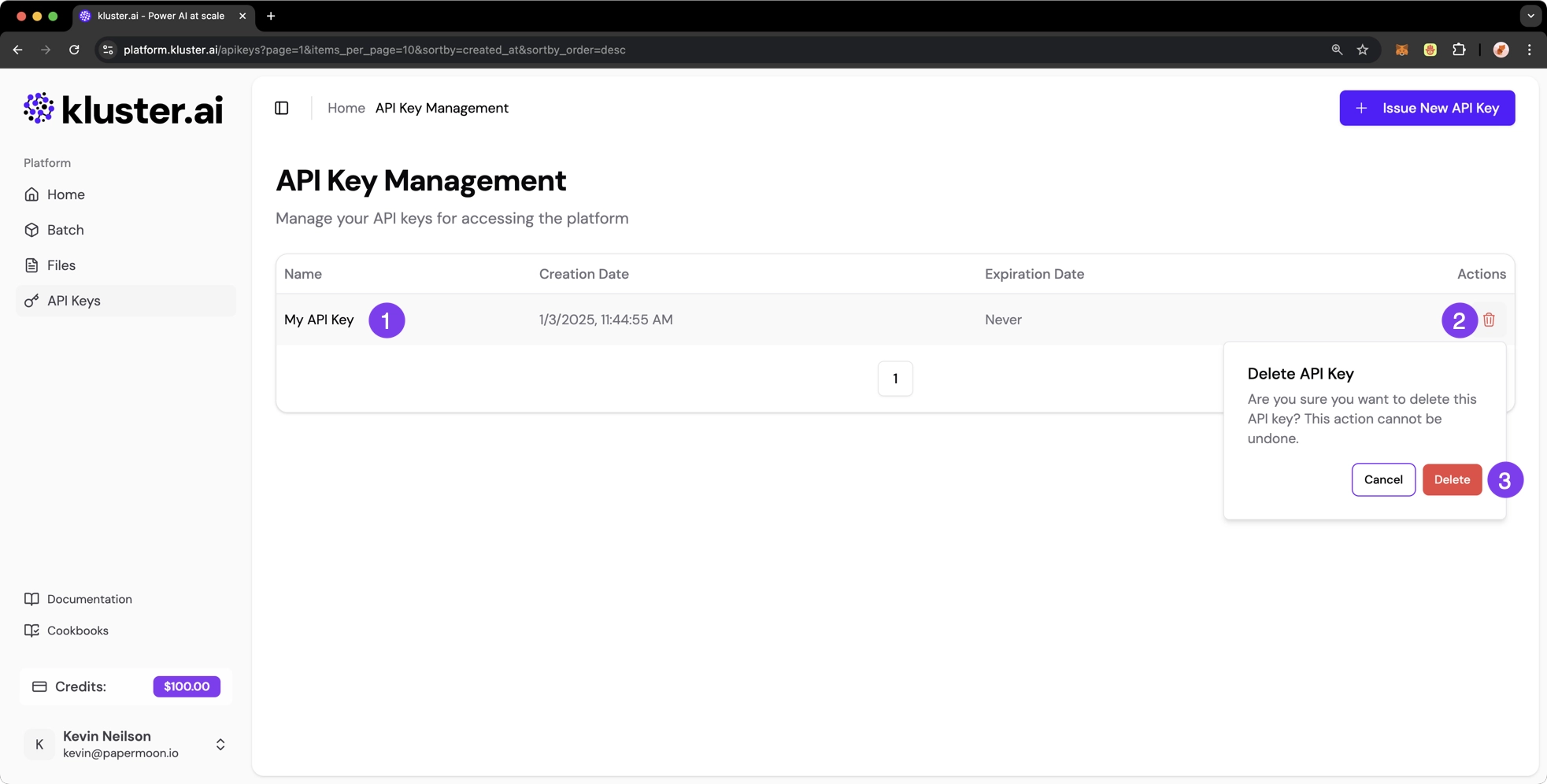
Warning
Once deleted, the API key cannot be used again and you must generate a new one if needed.
Next steps#
Now that you have your API key, you can start integrating kluster.ai's LLMs into your applications. Refer to our Getting Started guide for detailed instructions on using the API.